
Small. Fast. Reliable.
Choose any three.
Choose any three.
The SELECT statement is used to query the database. The result of a SELECT is zero or more rows of data where each row has a fixed number of columns. A SELECT statement does not make any changes to the database.
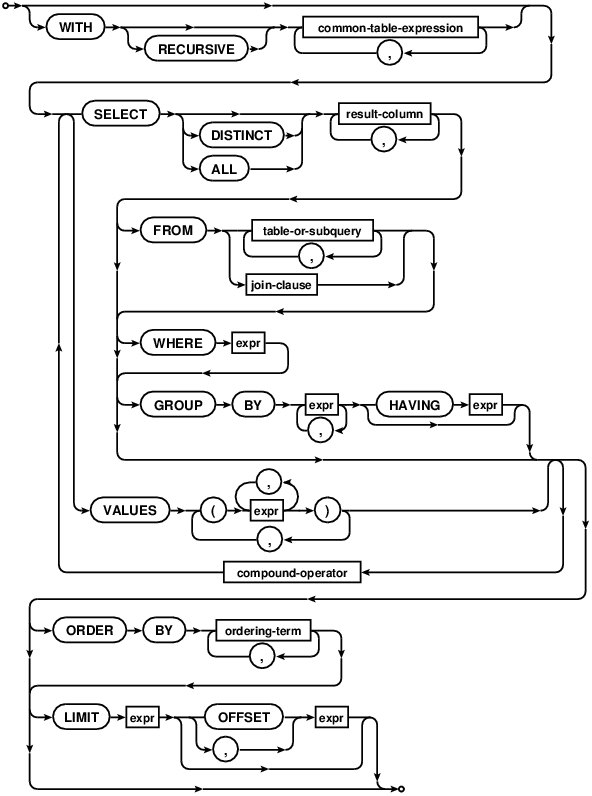
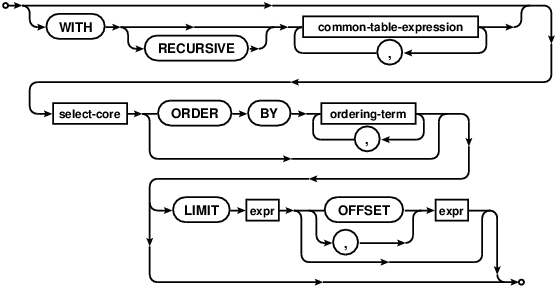
The "select-stmt" syntax diagram above attempts to show as much of the SELECT statement syntax as possible in a single diagram, because some readers find that helpful. The following "factored-select-stmt" is an alternative syntax diagrams that expresses the same syntax but tries to break the syntax down into smaller chunks.
Note that there are paths through the syntax diagrams that are not allowed in practice. Some examples:
The SELECT statement is the most complicated command in the SQL language. To make the description easier to follow, some of the passages below describe the way the data returned by a SELECT statement is determined as a series of steps. It is important to keep in mind that this is purely illustrative - in practice neither SQLite nor any other SQL engine is required to follow this or any other specific process.
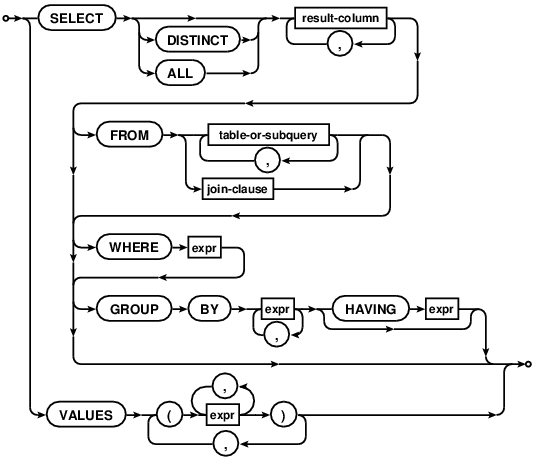
The core of a SELECT statement is a "simple SELECT" shown by the select-core and simple-select-stmt syntax diagrams below. In practice, most SELECT statements are simple SELECT statements.
Generating the results of a simple SELECT statement is presented as a four step process in the description below:
FROM clause processing: The input data for the simple SELECT is determined. The input data is either implicitly a single row with 0 columns (if there is no FROM clause) or is determined by the FROM clause.
WHERE clause processing: The input data is filtered using the WHERE clause expression.
GROUP BY, HAVING and result-column expression processing: The set of result rows is computed by aggregating the data according to any GROUP BY clause and calculating the result-set expressions for the rows of the filtered input dataset.
DISTINCT/ALL keyword processing: If the query is a "SELECT DISTINCT" query, duplicate rows are removed from the set of result rows.
There are two types of simple SELECT statement - aggregate and non-aggregate queries. R-20637-43463:[A simple SELECT statement is an aggregate query if it contains either a GROUP BY clause or one or more aggregate functions in the result-set. ] R-23155-55597:[Otherwise, if a simple SELECT contains no aggregate functions or a GROUP BY clause, it is a non-aggregate query. ]
1. Determination of input data (FROM clause processing).
The input data used by a simple SELECT query is a set of N rows each M columns wide.
R-16074-54196:[If the FROM clause is omitted from a simple SELECT statement, then the input data is implicitly a single row zero columns wide ] (i.e. N=1 and M=0).
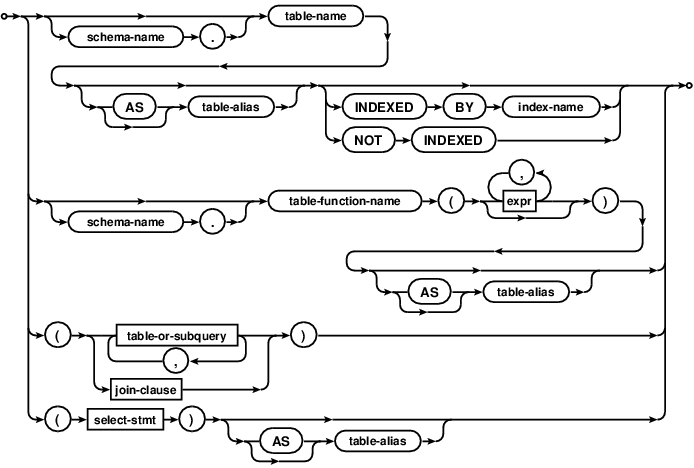
If a FROM clause is specified, the data on which a simple SELECT query operates comes from the one or more tables or subqueries (SELECT statements in parenthesis) specified following the FROM keyword. R-59237-46742:[A subquery specified in the table-or-subquery following the FROM clause in a simple SELECT statement is handled as if it was a table containing the data returned by executing the subquery statement. ] R-27438-53558:[Each column of the subquery has the collation sequence and affinity of the corresponding expression in the subquery statement. ]
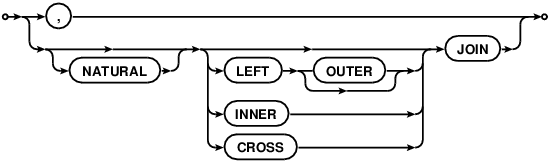
R-45424-07352:[If there is only a single table or subquery in the FROM clause, then the input data used by the SELECT statement is the contents of the named table. ] R-28355-09804:[If there is more than one table or subquery in FROM clause then the contents of all tables and/or subqueries are joined into a single dataset for the simple SELECT statement to operate on. ] Exactly how the data is combined depends on the specific join-operator and join-constraint used to connect the tables or subqueries together.
All joins in SQLite are based on the cartesian product of the left and right-hand datasets. R-59089-25828:[The columns of the cartesian product dataset are, in order, all the columns of the left-hand dataset followed by all the columns of the right-hand dataset. ] R-44414-54710:[There is a row in the cartesian product dataset formed by combining each unique combination of a row from the left-hand and right-hand datasets. ] R-18439-38548:[In other words, if the left-hand dataset consists of Nleft rows of Mleft columns, and the right-hand dataset of Nright rows of Mright columns, then the cartesian product is a dataset of Nleft×Nright rows, each containing Mleft+Mright columns. ]
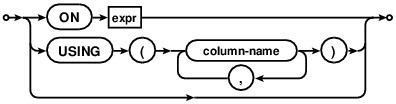
R-49872-03192:[If the join-operator is "CROSS JOIN", "INNER JOIN", "JOIN" or a comma (",") and there is no ON or USING clause, then the result of the join is simply the cartesian product of the left and right-hand datasets. ] If join-operator does have ON or USING clauses, those are handled according to the following bullet points:
R-38465-03616:[If there is an ON clause then the ON expression is evaluated for each row of the cartesian product as a boolean expression. Only rows for which the expression evaluates to true are included from the dataset. ]
R-49933-05137:[If there is a USING clause then each of the column names specified must exist in the datasets to both the left and right of the join-operator. ] R-22776-52830:[For each pair of named columns, the expression "lhs.X = rhs.X" is evaluated for each row of the cartesian product as a boolean expression. Only rows for which all such expressions evaluates to true are included from the result set. ] R-54046-48600:[When comparing values as a result of a USING clause, the normal rules for handling affinities, collation sequences and NULL values in comparisons apply. ] R-38422-04402:[The column from the dataset on the left-hand side of the join-operator is considered to be on the left-hand side of the comparison operator (=) for the purposes of collation sequence and affinity precedence. ]
R-57047-10461:[For each pair of columns identified by a USING clause, the column from the right-hand dataset is omitted from the joined dataset. ] R-56132-15700:[This is the only difference between a USING clause and its equivalent ON constraint. ]
R-04932-55942:[If the NATURAL keyword is in the join-operator then an implicit USING clause is added to the join-constraints. The implicit USING clause contains each of the column names that appear in both the left and right-hand input datasets. ] R-49566-01570:[If the left and right-hand input datasets feature no common column names, then the NATURAL keyword has no effect on the results of the join. ] R-39625-59133:[A USING or ON clause may not be added to a join that specifies the NATURAL keyword. ]
R-42531-52874:[If the join-operator is a "LEFT JOIN" or "LEFT OUTER JOIN", then after the ON or USING filtering clauses have been applied, an extra row is added to the output for each row in the original left-hand input dataset that corresponds to no rows at all in the composite dataset (if any). ] R-15607-52988:[The added rows contain NULL values in the columns that would normally contain values copied from the right-hand input dataset. ]
R-28760-53843:[When more than two tables are joined together as part of a FROM clause, the join operations are processed in order from left to right. In other words, the FROM clause (A join-op-1 B join-op-2 C) is computed as ((A join-op-1 B) join-op-2 C). ]
Side note: Special handling of CROSS JOIN. R-46256-57243:[There is no difference between the "INNER JOIN", "JOIN" and "," join operators. ] They are completely interchangeable in SQLite. R-25071-21202:[The "CROSS JOIN" join operator produces the same result as the "INNER JOIN", "JOIN" and "," operators ] , but is handled differently by the query optimizer in that it prevents the query optimizer from reordering the tables in the join. An application programmer can use the CROSS JOIN operator to directly influence the algorithm that is chosen to implement the SELECT statement. Avoid using CROSS JOIN except in specific situations where manual control of the query optimizer is desired. Avoid using CROSS JOIN early in the development of an application as doing so is a premature optimization. The special handling of CROSS JOIN is an SQLite-specific feature and is not a part of standard SQL.
2. WHERE clause filtering.
R-60775-64916:[If a WHERE clause is specified, the WHERE expression is evaluated for each row in the input data as a boolean expression. Only rows for which the WHERE clause expression evaluates to true are included from the dataset before continuing. ] Rows are excluded from the result if the WHERE clause evaluates to either false or NULL.
For a JOIN or INNER JOIN or CROSS JOIN, there is no difference between a constraint expression in the WHERE clause and one in the ON clause. However, for a LEFT JOIN or LEFT OUTER JOIN, the difference is very important. In a LEFT JOIN, the extra NULL row for the right-hand table is added after ON clause processing but before WHERE clause processing. A constraint of the form "left.x=right.y" in an ON clause will therefore allow through the added all-NULL rows of the right table. But if that same constraint is in the WHERE clause a NULL in "right.y" will prevent the expression "left.x=right.y" from being true, and thus exclude that row from the output.
3. Generation of the set of result rows.
Once the input data from the FROM clause has been filtered by the WHERE clause expression (if any), the set of result rows for the simple SELECT are calculated. Exactly how this is done depends on whether the simple SELECT is an aggregate or non-aggregate query, and whether or not a GROUP BY clause was specified.
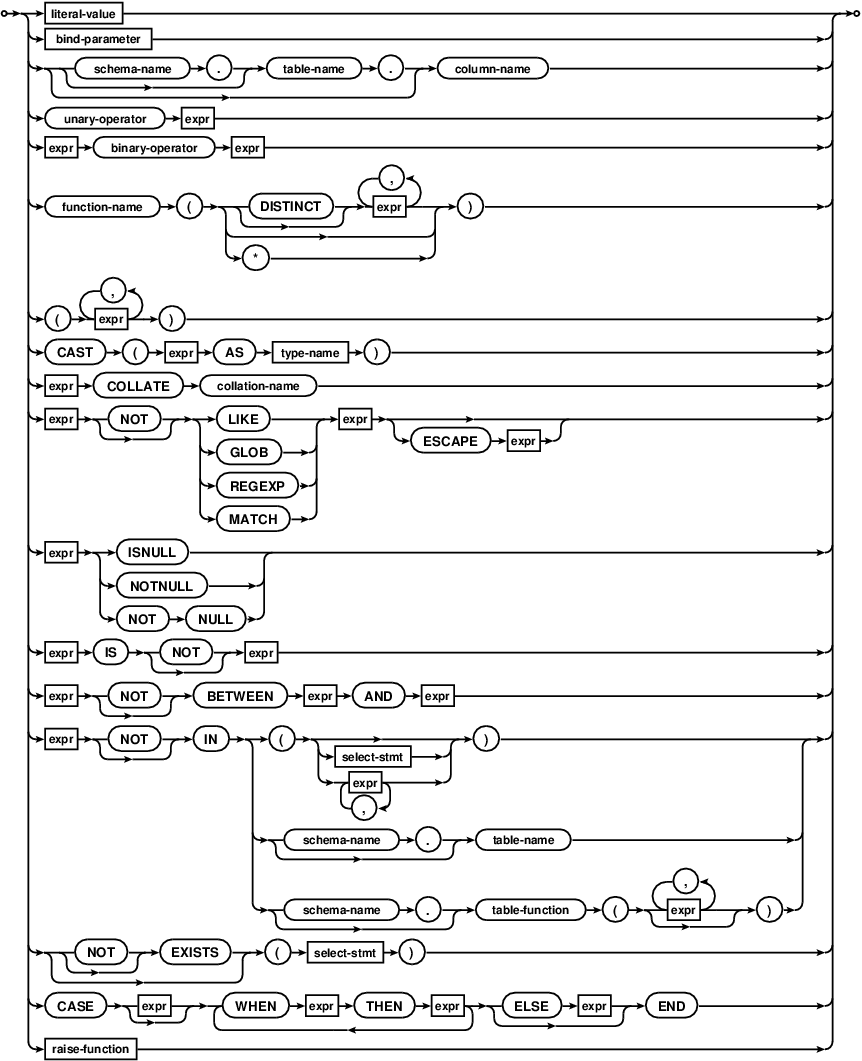
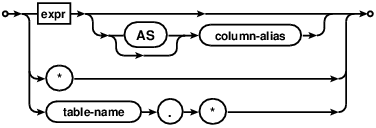
The list of expressions between the SELECT and FROM keywords is known as the result expression list. R-36327-17224:[If a result expression is the special expression "*" then all columns in the input data are substituted for that one expression. ] R-43693-30522:[If the expression is the alias of a table or subquery in the FROM clause followed by ".*" then all columns from the named table or subquery are substituted for the single expression. ] R-38023-18396:[It is an error to use a "*" or "alias.*" expression in any context other than a result expression list. ] R-44324-41166:[It is also an error to use a "*" or "alias.*" expression in a simple SELECT query that does not have a FROM clause. ]
R-08669-22397:[The number of columns in the rows returned by a simple SELECT statement is equal to the number of expressions in the result expression list after substitution of * and alias.* expressions. ] Each result row is calculated by evaluating the expressions in the result expression list with respect to a single row of input data or, for aggregate queries, with respect to a group of rows.
R-44050-47362:[If the SELECT statement is a non-aggregate query, then each expression in the result expression list is evaluated for each row in the dataset filtered by the WHERE clause. ]
R-57629-25253:[If the SELECT statement is an aggregate query without a GROUP BY clause, then each aggregate expression in the result-set is evaluated once across the entire dataset. ] R-26684-40576:[Each non-aggregate expression in the result-set is evaluated once for an arbitrarily selected row of the dataset. ] R-27994-60376:[The same arbitrarily selected row is used for each non-aggregate expression. ] R-04486-07266:[Or, if the dataset contains zero rows, then each non-aggregate expression is evaluated against a row consisting entirely of NULL values. ]
R-51988-01124:[The single row of result-set data created by evaluating the aggregate and non-aggregate expressions in the result-set forms the result of an aggregate query without a GROUP BY clause. ] R-64138-28774:[An aggregate query without a GROUP BY clause always returns exactly one row of data, even if there are zero rows of input data. ]
R-07284-35990:[If the SELECT statement is an aggregate query with a GROUP BY clause, then each of the expressions specified as part of the GROUP BY clause is evaluated for each row of the dataset. Each row is then assigned to a "group" based on the results; rows for which the results of evaluating the GROUP BY expressions are the same get assigned to the same group. ] R-14926-50129:[For the purposes of grouping rows, NULL values are considered equal. ] R-10470-30318:[The usual rules for selecting a collation sequence with which to compare text values apply when evaluating expressions in a GROUP BY clause. ] R-25883-55063:[The expressions in the GROUP BY clause do not have to be expressions that appear in the result. ] R-63573-50730:[The expressions in a GROUP BY clause may not be aggregate expressions. ]
R-31537-00101:[If a HAVING clause is specified, it is evaluated once for each group of rows as a boolean expression. If the result of evaluating the HAVING clause is false, the group is discarded. ] R-04132-09474:[If the HAVING clause is an aggregate expression, it is evaluated across all rows in the group. ] R-28262-47447:[If a HAVING clause is a non-aggregate expression, it is evaluated with respect to an arbitrarily selected row from the group. ] R-55403-13450:[The HAVING expression may refer to values, even aggregate functions, that are not in the result. ]
R-23927-54081:[Each expression in the result-set is then evaluated once for each group of rows. ] R-53735-47017:[If the expression is an aggregate expression, it is evaluated across all rows in the group. ] R-62913-19830:[Otherwise, it is evaluated against a single arbitrarily chosen row from within the group. ] R-53924-08809:[If there is more than one non-aggregate expression in the result-set, then all such expressions are evaluated for the same row. ]
R-19334-12811:[Each group of input dataset rows contributes a single row to the set of result rows. ] R-02223-49279:[Subject to filtering associated with the DISTINCT keyword, the number of rows returned by an aggregate query with a GROUP BY clause is the same as the number of groups of rows produced by applying the GROUP BY and HAVING clauses to the filtered input dataset. ]
Side note: Bare columns in an aggregate queries. The usual case is that all column names in an aggregate query are either arguments to aggregate functions or else appear in the GROUP BY clause. A result column which contains a column name that is not within an aggregate function and that does not appear in the GROUP BY clause (if one exists) is called a "bare" column. Example:
SELECT a, b, sum(c) FROM tab1 GROUP BY a;
In the query above, the "a" column is part of the GROUP BY clause and so each row of the output contains one of the distinct values for "a". The "c" column is contained within the sum() aggregate function and so that output column is the sum of all "c" values in rows that have the same value for "a". But what is the result of the bare column "b"? The answer is that the "b" result will be the value for "b" in one of the input rows that form the aggregate. The problem is that you usually do not know which input row is used to compute "b", and so in many cases the value for "b" is undefined.
Special processing occurs occurs when the aggregate function is either min() or max(). Example:
When the min() or max() aggregate functions are used in an aggregate query, all bare columns in the result set take values from the input row which also contains the minimum or maximum. So in the query above, the value of the "b" column in the output will be the value of the "b" column in the input row that has the largest "c" value. There is still an ambiguity if two or more of the input rows have the same minimum or maximum value or if the query contains more than one min() and/or max() aggregate function. Only the built-in min() and max() functions work this way.SELECT a, b, max(c) FROM tab1 GROUP BY a;
4. Removal of duplicate rows (DISTINCT processing).
R-60770-10612:[One of the ALL or DISTINCT keywords may follow the SELECT keyword in a simple SELECT statement. ] R-08861-34280:[If the simple SELECT is a SELECT ALL, then the entire set of result rows are returned by the SELECT. ] R-01256-01950:[If neither ALL or DISTINCT are present, then the behavior is as if ALL were specified. ] R-14442-41305:[If the simple SELECT is a SELECT DISTINCT, then duplicate rows are removed from the set of result rows before it is returned. ] R-02054-15343:[For the purposes of detecting duplicate rows, two NULL values are considered to be equal. ] R-47709-27231:[The usual rules apply for selecting a collation sequence to compare text values. ]
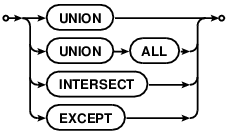
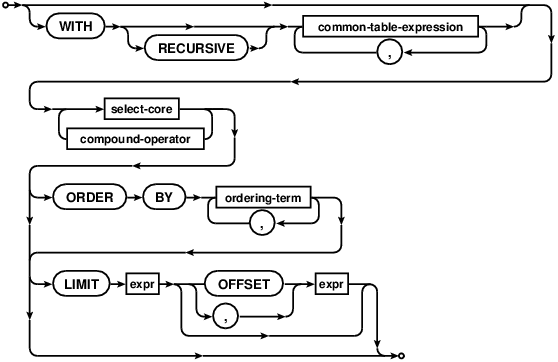
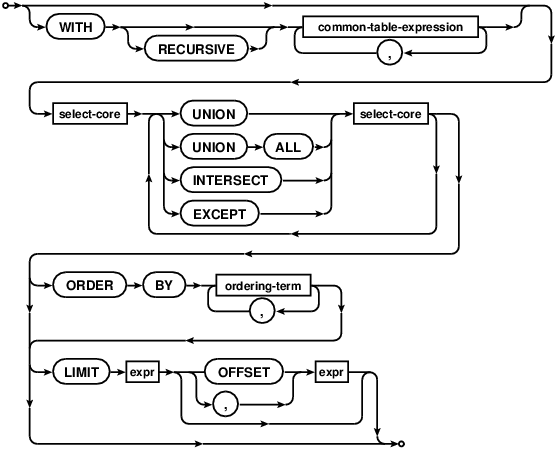
Two or more simple SELECT statements may be connected together to form a compound SELECT using the UNION, UNION ALL, INTERSECT or EXCEPT operator, as shown by the following diagram:
R-39368-64333:[In a compound SELECT, all the constituent SELECTs must return the same number of result columns. ] R-01450-11152:[As the components of a compound SELECT must be simple SELECT statements, they may not contain ORDER BY or LIMIT clauses. ] R-45440-25633:[ORDER BY and LIMIT clauses may only occur at the end of the entire compound SELECT, and then only if the final element of the compound is not a VALUES clause. ]
R-08531-36543:[A compound SELECT created using UNION ALL operator returns all the rows from the SELECT to the left of the UNION ALL operator, and all the rows from the SELECT to the right of it. ] R-20560-39162:[The UNION operator works the same way as UNION ALL, except that duplicate rows are removed from the final result set. ] R-45764-31737:[The INTERSECT operator returns the intersection of the results of the left and right SELECTs. ] R-25787-28949:[The EXCEPT operator returns the subset of rows returned by the left SELECT that are not also returned by the right-hand SELECT. ] R-40729-56447:[Duplicate rows are removed from the results of INTERSECT and EXCEPT operators before the result set is returned. ]
R-46765-43362:[For the purposes of determining duplicate rows for the results of compound SELECT operators, NULL values are considered equal to other NULL values and distinct from all non-NULL values. ] R-51232-50224:[The collation sequence used to compare two text values is determined as if the columns of the left and right-hand SELECT statements were the left and right-hand operands of the equals (=) operator, except that greater precedence is not assigned to a collation sequence specified with the postfix COLLATE operator. ] R-32706-07403:[No affinity transformations are applied to any values when comparing rows as part of a compound SELECT. ]
R-32562-20566:[When three or more simple SELECTs are connected into a compound SELECT, they group from left to right. In other words, if "A", "B" and "C" are all simple SELECT statements, (A op B op C) is processed as ((A op B) op C). ]
If a SELECT statement that returns more than one row does not have an ORDER BY clause, the order in which the rows are returned is undefined. Or, if a SELECT statement does have an ORDER BY clause, then the list of expressions attached to the ORDER BY determine the order in which rows are returned to the user.
R-02644-22131:[In a compound SELECT statement, only the last or right-most simple SELECT may have an ORDER BY clause. ] R-34494-34867:[That ORDER BY clause will apply across all elements of the compound. ] R-38644-64912:[If the right-most element of a compound SELECT is a VALUES clause, then no ORDER BY clause is allowed on that statement. ]
R-44988-41064:[Rows are first sorted based on the results of evaluating the left-most expression in the ORDER BY list, then ties are broken by evaluating the second left-most expression and so on. ] The order in which two rows for which all ORDER BY expressions evaluate to equal values are returned is undefined. R-06617-54588:[Each ORDER BY expression may be optionally followed by one of the keywords ASC (smaller values are returned first) or DESC (larger values are returned first). ] R-18705-33393:[If neither ASC or DESC are specified, rows are sorted in ascending (smaller values first) order by default. ]
Each ORDER BY expression is processed as follows:
R-29779-04281:[If the ORDER BY expression is a constant integer K then the expression is considered an alias for the K-th column of the result set (columns are numbered from left to right starting with 1). ]
R-63286-51977:[If the ORDER BY expression is an identifier that corresponds to the alias of one of the output columns, then the expression is considered an alias for that column. ]
R-65068-27207:[Otherwise, if the ORDER BY expression is any other expression, it is evaluated and the returned value used to order the output rows. ] R-03421-57988:[If the SELECT statement is a simple SELECT, then an ORDER BY may contain any arbitrary expressions. ] R-28853-08147:[However, if the SELECT is a compound SELECT, then ORDER BY expressions that are not aliases to output columns must be exactly the same as an expression used as an output column. ]
R-10883-17697:[For the purposes of sorting rows, values are compared in the same way as for comparison expressions. ] The collation sequence used to compare two text values is determined as follows:
R-64199-22471:[If the ORDER BY expression is assigned a collation sequence using the postfix COLLATE operator, then the specified collation sequence is used. ]
R-09398-26102:[Otherwise, if the ORDER BY expression is an alias to an expression that has been assigned a collation sequence using the postfix COLLATE operator, then the collation sequence assigned to the aliased expression is used. ]
R-27301-09658:[Otherwise, if the ORDER BY expression is a column or an alias of an expression that is a column, then the default collation sequence for the column is used. ]
R-49925-55905:[Otherwise, the BINARY collation sequence is used. ]
In a compound SELECT statement, all ORDER BY expressions are handled as aliases for one of the result columns of the compound. R-44130-32593:[If an ORDER BY expression is not an integer alias, then SQLite searches the left-most SELECT in the compound for a result column that matches either the second or third rules above. If a match is found, the search stops and the expression is handled as an alias for the result column that it has been matched against. Otherwise, the next SELECT to the right is tried, and so on. ] R-39265-04070:[If no matching expression can be found in the result columns of any constituent SELECT, it is an error. ] R-03407-11483:[Each term of the ORDER BY clause is processed separately and may be matched against result columns from different SELECT statements in the compound. ]
R-37911-51642:[The LIMIT clause is used to place an upper bound on the number of rows returned by the entire SELECT statement. ]
R-13512-64012:[In a compound SELECT, only the last or right-most simple SELECT may contain a LIMIT clause. ] R-03782-50113:[In a compound SELECT, the LIMIT clause applies to the entire compound, not just the final SELECT. ] R-65380-53022:[If the right-most simple SELECT is a VALUES clause then no LIMIT clause is allowed. ]
R-30481-56627:[Any scalar expression may be used in the LIMIT clause, so long as it evaluates to an integer or a value that can be losslessly converted to an integer. ] R-46155-47219:[If the expression evaluates to a NULL value or any other value that cannot be losslessly converted to an integer, an error is returned. ] R-03014-26414:[If the LIMIT expression evaluates to a negative value, then there is no upper bound on the number of rows returned. ] R-33750-29536:[Otherwise, the SELECT returns the first N rows of its result set only, where N is the value that the LIMIT expression evaluates to. ] R-54935-19057:[Or, if the SELECT statement would return less than N rows without a LIMIT clause, then the entire result set is returned. ]
R-24188-24349:[The expression attached to the optional OFFSET clause that may follow a LIMIT clause must also evaluate to an integer, or a value that can be losslessly converted to an integer. ] R-20467-43422:[If an expression has an OFFSET clause, then the first M rows are omitted from the result set returned by the SELECT statement and the next N rows are returned, where M and N are the values that the OFFSET and LIMIT clauses evaluate to, respectively. ] R-34648-44875:[Or, if the SELECT would return less than M+N rows if it did not have a LIMIT clause, then the first M rows are skipped and the remaining rows (if any) are returned. ] R-23293-62447:[If the OFFSET clause evaluates to a negative value, the results are the same as if it had evaluated to zero. ]
R-19509-40356:[Instead of a separate OFFSET clause, the LIMIT clause may specify two scalar expressions separated by a comma. ] R-33788-46243:[In this case, the first expression is used as the OFFSET expression and the second as the LIMIT expression. ] This is counter-intuitive, as when using the OFFSET clause the second of the two expressions is the OFFSET and the first the LIMIT. This reversal of the offset and limit is intentional - it maximizes compatibility with other SQL database systems. However, to avoid confusion, programmers are strongly encouraged to use the form of the LIMIT clause that uses the "OFFSET" keyword and avoid using a LIMIT clause with a comma-separated offset.
R-35668-58241:[The phrase "VALUES(expr-list)" means the same thing as "SELECT expr-list". ] R-47188-50799:[The phrase "VALUES(expr-list-1),...,(expr-list-N)" means the same thing as "SELECT expr-list-1 UNION ALL ... UNION ALL SELECT expr-list-N". ] Both forms are the same, except that the number of SELECT statements in a compound is limited by SQLITE_LIMIT_COMPOUND_SELECT whereas the number of rows in a VALUES clause has no arbitrary limit.
There are some restrictions on the use of a VALUES clause that are not shown on the syntax diagrams:
R-12747-43999:[A VALUES clause cannot be followed by ORDER BY. ]
R-12259-19638:[A VALUES clause cannot be followed by LIMIT. ]
R-32586-01296:[SELECT statements may be optionally preceded by a single WITH clause that defines one or more common table expressions for use within the SELECT statement. ]
A virtual table that contains hidden columns can be used like a table-valued function in the FROM clause. The arguments to the table-valued function become constraints on the HIDDEN columns of the virtual table. Additional information can be found in the virtual table documentation.
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]
 ]
]